The challenge
build a resilient storage solution on commodity hardware with minimal cost.
Our answer: a high performance five node CEPH cluster for less than 7.000€*

*Prices exclude hard drives / you can expect the same prices in US$
What you will learn
- facts for decision makers on how to structure a basic (hyperconverged?) CEPH cluster
- how to achieve your performance goal
- minimize your hardware invest
- save grey energy
- what to avoid and
- what to consider
- what to expect
- in performance
- availability
- power consumption
- convenience
- … and more
What you will not learn is how to setup CEPH, Proxmox, KVM, Linux, Networking and all other basics, described often enough somewhere else on the internet. Key technologies and methods we used are linked directly or referenced at the end of the document.
In Part 2 - Getting productive we will describe the steps from the test setup to production and the learnings we’ve made including our investment overview.
In Part 3 - Compute Power we will describe how to add proper computing power for under 5000 Euro to utiliize your CEPH cluster and do sexy stuff like mass live-migration of VM’s
In Part 4 - Taming the beast we show you how to run, monitor and troubleshoot your cluster
How it all began
FreshX is an agile software development company. Not to bring in too many buzzwords, we run a very streamlined software development lifecycle including version control, a CI and a CD. Furthermore we are hosting most of our customers IoT setups in our datacenter. Until last year we were running a typical co-hosted datacenter setup. A rack, a simple switch, a bunch of servers running Linux and KVM and a bit of Ansible config management on top. So far so good, it all worked fairly well, but migrating VM’s between servers was a pain for us and our customers. Furthermore everything was done in the good old command line style manually. Then we got - by chance - a generous offer of two 10GE switches and somehow, we got ants in the pants using them for more than just pushing packet around…
But let’s start with the old setup. What we had was a typically grown setup as shown in the following picture, with a simple redundant gigabit switch.
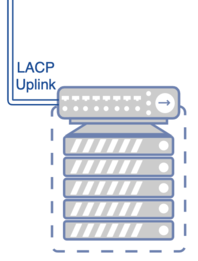
Each server was setup with CentOS 7 and we were running approx 40 KVM based virtual machines. Everything was setup redundant, the local storage, the power supplies, the power phases, as I learned in school ;-). We consumed around 380 Watt per phase with four 11th Generation Dell Servers (Intel E5xxx CPU’s), a simple TP-Link switch connected with LACP. Besides the hardware growing old our pain nailed down to the questions we discussed over and over again, how to:
update the core servers without downtimes for critical customer VM’s
get flexibility in cwcore server maintenance without negotiating with all stakeholders
rebalance server resources (RAM, CPU and storage) easily
get resilient to hardware failures
get a redundant network setup without running STP
be ready for further growth
standardize the hardware and the VM setup
get an overview of the low level infrastructure and its health state
In short : we wanted the performance pooping, absolut resilient, simple and cheap - but still good looking - secure datacenter unicorn
To iSCSI or not to iSCSI
By the time we acquired those 10GE switches I was already fancying some old second hand Dell Equallogic iSCSI boxes which I was running in my old job back at university but despite the fact that I liked them a lot, I was hesitating due to
- power consumption
- pricing (~4k per box for the 10GE variants)
- lack of vendor or community support
- lack of access to software (you want to run the Dell multipath stack)
- not very elastic in growing
But what would we do then with our nice two 10GE switches? My fellow admin Florian and me had repeating, endless and sometimes exhausting discussions about our future setup running iSCSI, ZFS, NFS, clustered filesystems, hyperconverged all-in-one-unicorns and so on. And - we hardly had a clue about what is really possible in regards of performance over the wire (for IOPS and throughput). And since we are not the kind of company which quickly takes 20k and goes for a full blown testbed, we had to make up our mind already upfront.
By chance I ran over three super cheap bareboned Dell PowerEdge R520 servers (Generation 12, E5-24xx CPU’s) which I acquired and built up to become working boxes including 10GE Ethernet cards. We initially tested NIC’s from HP with NCP523 Chips (really low price cards) and Intel X520 NIC’s but we were not really satisfied with the handling, firmware updates and the support on current Linux systems and finally ended up with Dual-Port Mellanox Connect X Cards, (Connect-X and the Connect-X2 EN are the same, whereas the Connect-X3 EN has a newer chipset).
It was also clear for us to start with big 12Gb/s SAS HDD’s where we would choose HGST 10TB in the beginning, switching to Seagate later due to disk timeout’s in SAS 12Gb/s mode of the HGST.
Our first testbed
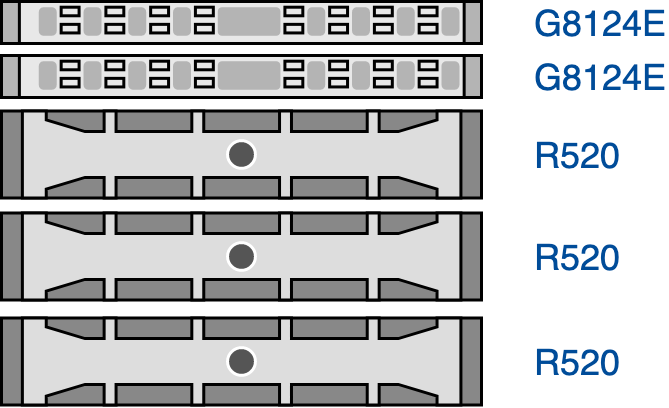
After a last painful back-and-forth discussion, we chose to go for a CEPH based storage cluster based on the Proxmox Virtual Environment (PVE) and stick to what the basic system offers as standard and avoid manual CEPH tweaks under the hood. Our initial setup looked like this
- Dell PowerEdge R520
- 16 Core E5-2470 @ 2.3GHz
- 48GB DDR3 memory
- LFF HDD Slots with space for up to 8 disks per chassis
- SAS HBA : LSI3008 based SAS-3 Controller (IBM M1215, avoid the Dell H330)
- two proper SuperMicro SAS-3 SFF-8643 to SFF-8087 cables per box to directly connect to the R520 backplane (which works with SAS 12Gb/s!)
- Mellanox CX312-EN Ethernet Adapter
- Seagate Exos X X10 10TB, 4Kn, SAS 12Gb/s
- Proxmox PVE 5.4 on each node
- CD-Rom ssd adapter caddy (we gonna place to OS disk here to save another slot)
Price Tag: approxmately 930 Euro for one fully exquipped box + 660 Euro for two Seagate X10 1TB SAS 12Gb/s
Our first testbed looked like this
A note on the hardware

The Dell R520 seemed to us like a perfect platform, since it runs DDR3 memory on a fair price and the backplane allows for 12Gb/s SAS-3. The Dell R720 with LFF should do as well but avoid the 720SFF/720xd which looks nice and comes with a lot of HDD slots but has a SAS-Expander instead of a backplane to support the 14 drives which it can ship. This SAS-Expander will forcibly pull you down to SAS-2 running with 6Gb/s which is ok for the spinning disks but (spoiler alert) we would start to add SSD’s very soon.
Due to my old job im a heavy Dell disciple and we have no clue if other vendors (SuperMicro, HP or IBM) can be run with SAS-3 on their backplane.
If you have the money you could also go for 13th/14th generation servers (Dell R530/730 or R540/740). This gives you a guaranteed option for 12G SAS, vendor support, prepared systems for NVME’s, hence more free disk slots for storage and around 10% less power consumption. On the downside, CPU’s and DDR-4 memory are 2.5 times more expensive.
We chose the unsupported path since we trust the hardware platform and ultimatively will have one spare part of each critical component on stock. You will here need to find your right balance between invest and trust.
A note on network equipment

If you want proper stuff, you will pay but there are second hand options which are better than others. Our concern even today still is to have a replacement switch for the setup. If you go for options on the second hand-market, consider, that for some vendors (such as Blade/IBM or Dell) you most probably find firmware updates and public community support, whereas others such as Cisco or Juniper only provide this to valuable customers (say you have a valid supported contract, which is part of the business model). Check this upfront buying second-hand.
A note on the hyperconverged unicorn
Hyperconverged setups are the latest buzzwords from big vendors which shall allow you to mix storage boxes and compute boxes in one big clustered thing. While it sounds sexy in the beginning, look twice if someone wants to sell you the rose-smell pooping pink unicorn🦄or in short : Don’t!
In long : running a fully productive CEPH storage cluster will already be influenced by many factors such as
- core hardware (CPU, RAM, disks + controllers)
- caching mechanisms
- network design
- network hardware (latency, stability, throughput, …)
- network software (TCP stack, encryption, …)
- buffers on all layers (disk buffers, controller buffers, OS buffers, network buffers, TCP buffers, backpressure in the whole chain, …)
- CEPH itself and its (sometimes) very computation heavy algorithms
- …
In case of problems (it’s not just a simple RAID controller to exchange) you will find yourself in a long process of searching and testing - we talk about this in Part 4. Don’t throw another hard to predict variable into the ring.
Back to the whiteboard
I have to say that I’m an easy going guy, sometimes too easy going, such as
Let’s quickly try this fix! Ooops … Or I realize, that we want/need to update this VM? Well if no one is looking, lets quickly do it. Florian is - praise the lord - my counterpart, working very detailed and exact and we learned over the last years to mix our qualities nicely together highly reducing the length of our chalk board discussions. My view after the the first testbed run was
- let’s go! HDD gives me write thoughputs of 250MB/s on large buffer size, that should do!
- three storage nodes for a clustered setup should be fine, no? (no split brain possible - that’s enough)
- SSD’s are really too expensive, let’s try to pimp up our setup (maybe with some caching Intel Optanes?)
- …
Florian on the other hand was like : i will not run that setup in production, unless we meet certain basic criteria such as :
- a clear network strategy regarding availability and performance
- redundancy is still an issue for system disks (we are running the OS disk on a single disk in the CDRom slot)!
- the final setup must consist of 5 storage nodes
- can we not have enterprise components with vendor support?
Well, we ended up with the following agreement, which is also our recommendation for a basic productive setup
Recommended minimal CEPH setup
- be(come) clear about your general setup
- be(come) clear about all potential points of failure
- be clear about your network setup, plan at least
- redundant switches with MLAG or similar (and test a failover)
- run the same switch hard and software
- a separate storage net
- a separate management + PVE cluster sync net
- a fallback network for management and the PVE cluster sync (on separate switching hardware)
- five storage boxes (respectively ceph monitors) shall be the minimum to have peaceful nights
- each data object is stored at three times in the cluster, dividing your brutto storage by the number of replica (we have 3)
- good CPU and RAM is important (16 cores @ 2.3GHz and 48GB seems like a good start, more won’t hurt, especially for SSD’s)
- good access to network component documentation or support is crucial for debugging in the network stack
- stick to the defaults unless you are an experienced CEPH admin
- get support for your software too (in case of Proxmox PVE, get at least the enterprise basic license)
- KISS (keep it simple and stupid)
So let’s finally start
After clearing this out, we prepared a plan on how to finance the endeavor and what we would need to start, which took us two month to get all the boxes equipped with 2 x 10TB HDD’s each, 10GE network + cabling and suiting SAS3 HBA Controllers.
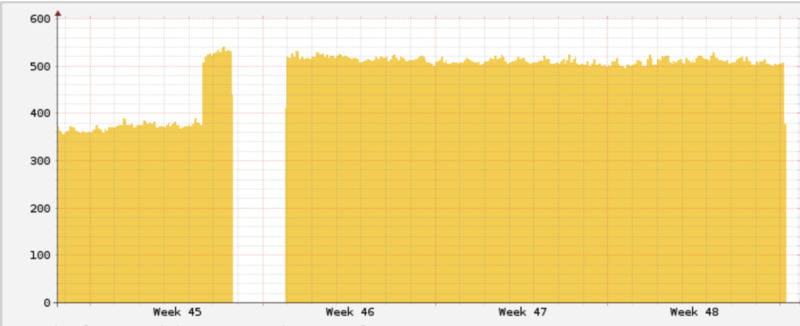
Meanwhile we prepared our datacenter so that our existing infrastructure was moved to the 10GE network infrastructure and the servers have been connected with 802.3ad LACP bonds. Despite me plugging a network loop at our colocation💩(making me the most valuable employee in December), everything worked very well and solved already our network redundancy problem✅but also pushed up our average wattage to 500W (redundant 10GE networking does not come for free!)
Part 2
Well. This is the end of Part 1. In Part 2 (From testbed to productive) we will go into more details such as
- some network latency math
- what about slow HDDs and what about putting CEPH journals on Intel Optanes
- what performance will we squeeze out eventually
- hands-on stuffing all the components together
- what happens if one box simply dies?
- tips on hardware acquire for the more professional
Part 3
In Part 3 (Adding a four node compute cluster with 80 cores and 0.5TB RAM for less than 5000 Euro) we gonna add some beefy 3GHz compute nodes to our storage setup and migrate our old datacenter into the new setup
- how does such a setup looks like
- best practice in migrating VM data into CEPH
- best practices in the VM disk setup (HDD vs. SSD)
- what’s our expected wattage in the end?